The idea came from noticing that scrambled words are easier to read than you'd expect. Cambridge University's famous typoglycemia meme claims you can read jumbled text as long as the first and last letters stay put. That's an overstatement, but there's a kernel of truth: context does a lot of heavy lifting. I wanted to build a game that tests exactly how much.
{kind=link}
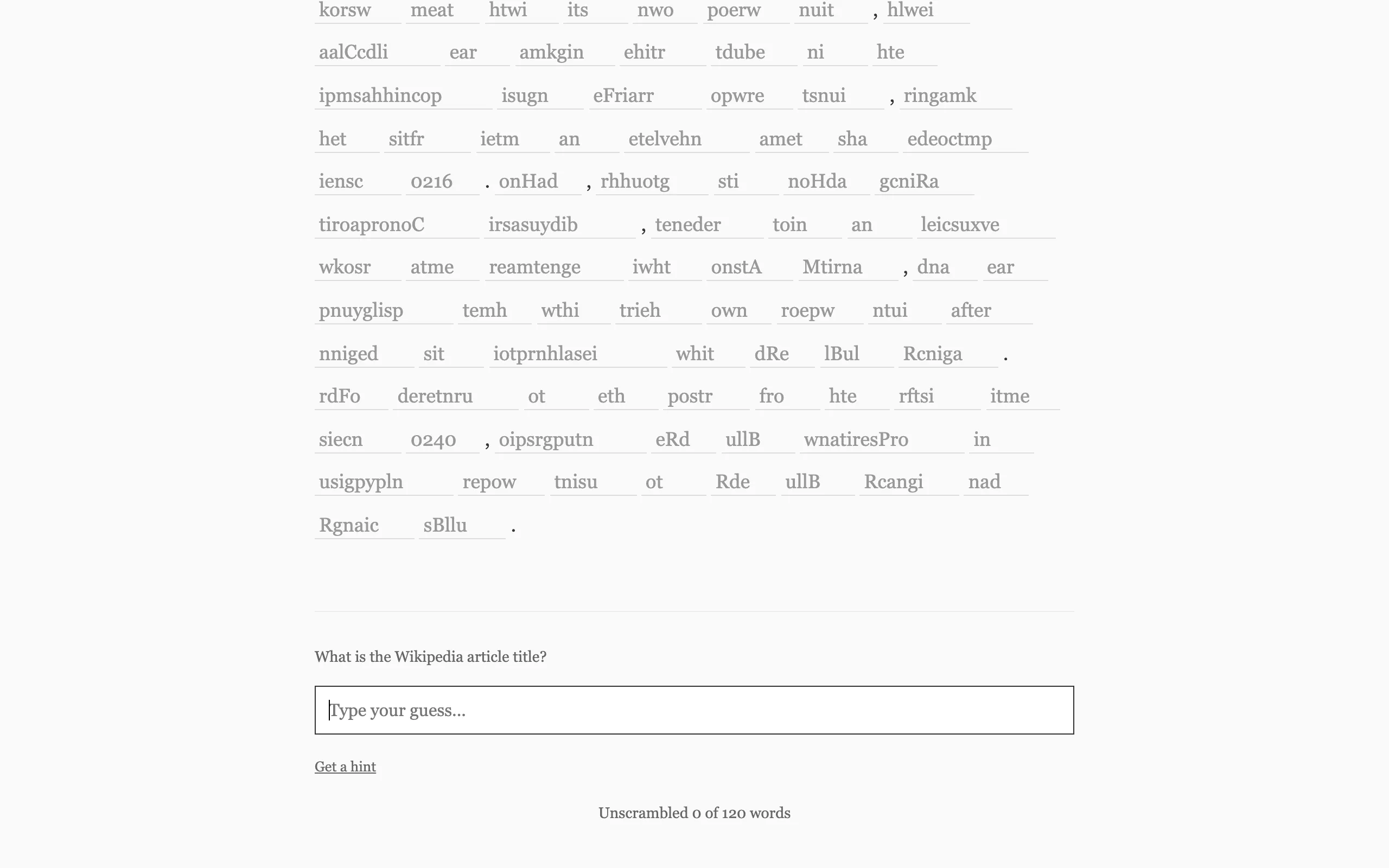
Wikipedia Unscrambler fetches a real article from the Wikipedia REST API, extracts a four-sentence passage, and scrambles each word. You see the jumbled text and try to unscramble individual words while also guessing the article title. The article content gives you thematic clues, so the two tasks reinforce each other: unscrambling a few words helps you guess the topic, and knowing the topic helps you unscramble the remaining words.
Difficulty tiers
Not all Wikipedia articles are equally recognizable. An article about the United States has vocabulary anyone would know. An article about a specific species of moth does not. The game uses Wikimedia's pageview statistics to sort articles by popularity, then slices them into three tiers. Easy mode draws from the top 50 most-viewed articles from the previous day. Medium pulls from ranks 50 to 200. Hard goes from 200 to 500. The result is that easy mode gives you articles about major countries, celebrities, and current events, while hard mode serves up articles you've probably never opened.
Daily view counts also mean the game content rotates naturally. A celebrity who trends on a given day will show up in easy mode that day and disappear the next. You never run out of fresh puzzles.
{kind=link}
How the scrambling works
Each word in the passage gets its letters shuffled randomly, with punctuation left in place. The scrambled version appears as placeholder text inside an input field. You type what you think the original word is, and if you're right, the field locks with a green indicator. A counter at the bottom tracks how many words you've solved out of the total.
The title guess is separate. Below the scrambled passage, there's a text input where you can guess the article title at any point. Three progressive hints are available if you get stuck: the character count, then the first letter, then the first word. These are enough to nudge you in the right direction without giving it away.
Implementation
The entire thing is a single HTML file with embedded JavaScript. No build step, no dependencies, no framework. The Wikipedia API does the heavy lifting on the content side. On page load, the app fetches yesterday's most-viewed articles, picks one at random from the appropriate tier, fetches its extract, splits it into sentences, and scrambles the words. Tab navigation cycles through the word inputs so you can play without touching the mouse.
Because the game state is self-contained in the browser, it's easy to share. Each difficulty level maintains its own state, so you can switch between easy and hard without losing progress on either.