
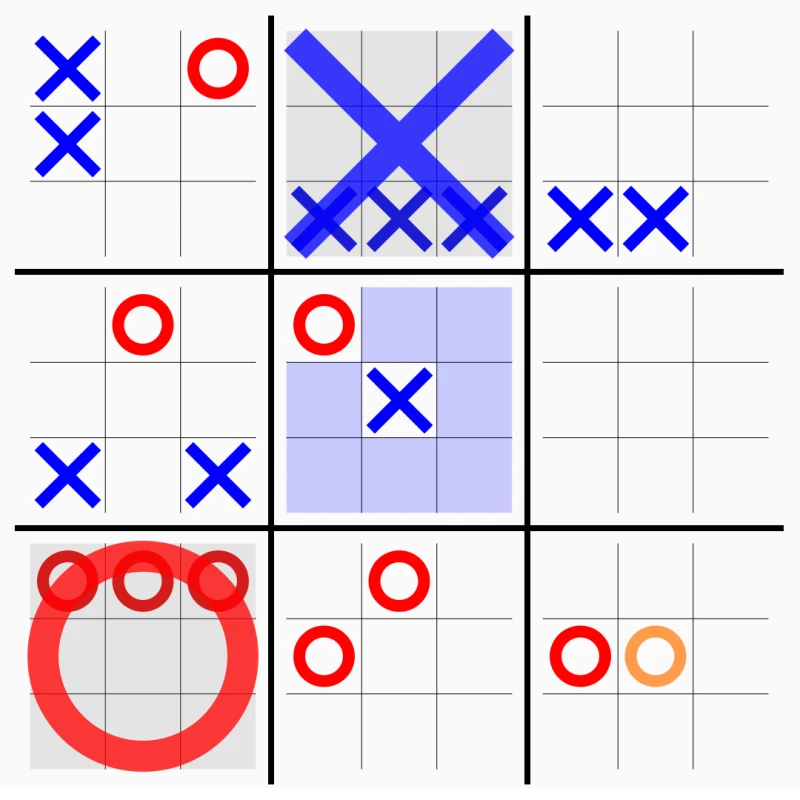
Ultimate tic-tac-toe takes a game that's been solved since childhood and makes it genuinely hard. The board is a 3x3 grid of smaller tic-tac-toe boards. To win, you need to claim three sub-boards in a row. But the twist is what makes it interesting: the cell you play in determines which sub-board your opponent must play in next. Pick the top-right cell of any sub-board, and your opponent is forced to play in the top-right sub-board. This constraint turns a game of local tactics into one of global strategy. Every move has consequences two layers deep.
{kind=link}
When you're sent to a sub-board that's already been won or filled, you get a free choice of any open sub-board. This rule prevents deadlocks and creates moments of sudden strategic opportunity. Sending your opponent to a completed board gives them freedom, which is usually bad for you.
The AI
The opponent uses minimax with alpha-beta pruning, searching three plies deep. Minimax models the game as a two-player zero-sum decision process. Given a game state \(s\), the algorithm computes a value \(V(s)\) by recursing over all legal moves and alternating between the two players. At terminal or depth-limited states, a heuristic evaluation function provides the base case. The recurrence is:
\[V(s) = \begin{cases} \text{eval}(s) & \text{if } s \text{ is terminal or depth limit reached} \\ \max_{a \in A(s)} V(s') & \text{if it is the maximizer's turn} \\ \min_{a \in A(s)} V(s') & \text{if it is the minimizer's turn} \end{cases}\]where \(A(s)\) is the set of legal actions in state \(s\) and \(s'\) is the successor state after taking action \(a\).
Game tree complexity
Three plies doesn't sound like much, but the branching factor in ultimate tic-tac-toe is large. When you're constrained to a single sub-board, there are up to 9 possible moves. When you have free choice (because the target sub-board is already won or filled), there can be dozens of legal moves spread across multiple open sub-boards. The effective branching factor \(b\) varies throughout the game but averages roughly \(b \approx 9\) in constrained positions and can spike above 40 in free-choice positions. With a search depth of \(d = 3\), a naive minimax explores on the order of \(O(b^d)\) nodes. In the constrained case that's \(9^3 = 729\) nodes; in free-choice positions it grows into the tens of thousands.
The full game tree for ultimate tic-tac-toe has been estimated at around \(10^{50}\) to \(10^{60}\) possible states, far too large to solve by brute force. For comparison, standard 3x3 tic-tac-toe has only \(9! = 362{,}880\) possible games and is trivially solved. The meta-level constraint is what makes exhaustive search infeasible and depth-limited heuristic search necessary.
Alpha-beta pruning
Alpha-beta pruning maintains two bounds during the search: \(\alpha\), the best value the maximizer can guarantee, and \(\beta\), the best value the minimizer can guarantee. A subtree is pruned whenever \(\alpha \geq \beta\), because the current player already has a better option elsewhere in the tree. Formally, the search becomes:
\[\text{alphabeta}(s, d, \alpha, \beta) = \begin{cases} \text{eval}(s) & \text{if } d = 0 \text{ or } s \text{ is terminal} \\ \max_{a \in A(s)} \text{alphabeta}(s', d-1, \alpha, \beta) & \text{maximizer, with } \alpha \leftarrow \max(\alpha, v) \\ \min_{a \in A(s)} \text{alphabeta}(s', d-1, \alpha, \beta) & \text{minimizer, with } \beta \leftarrow \min(\beta, v) \end{cases}\]with cutoff when \(\alpha \geq \beta\). With optimal move ordering, alpha-beta reduces the effective number of nodes explored from \(O(b^d)\) to \(O(b^{d/2})\), which is equivalent to searching twice as deep for the same cost. In practice, move ordering is imperfect, so the actual performance lies between these bounds: roughly \(O(b^{3d/4})\) for reasonable heuristic ordering. This is what keeps the search tractable at depth three even in free-choice positions.

{kind=link}
Evaluation function
The evaluation function scores board states at the leaves of the search tree. It calls evaluate_global(), which examines the meta-board (which sub-boards have been won by whom) and returns a numeric score. Positive values favor the maximizing player; negative values favor the minimizer.
Conceptually, for each of the eight winning lines \(\ell\) on the meta-board (three rows, three columns, two diagonals), the function computes a line score based on how many sub-boards each player has claimed along that line. Let \(x_\ell\) be the number of sub-boards won by the maximizer on line \(\ell\) and \(o_\ell\) the count for the minimizer. A line that contains marks from both players is blocked and contributes nothing. Otherwise, the evaluation is:
\[\text{eval}(s) = \sum_{\ell} \left( w(x_\ell) - w(o_\ell) \right)\]where \(w(k)\) is a weighting function that assigns increasing value to more marks on an unblocked line, such as \(w(0) = 0\), \(w(1) = 1\), \(w(2) = 10\), \(w(3) = +\infty\) (a win). This makes the AI value positions that threaten to complete a meta-row far more than isolated sub-board wins, and it captures both offensive and defensive priorities in a single scalar.
The Rust code is organized into separate modules for types, individual board logic, game state management, and the minimax search itself. types.rs defines the cell states and move structures. board.rs handles the 3x3 sub-board logic, including win detection. game.rs manages the full 9-board state and enforces the "your move picks their board" constraint. minimax.rs contains the search algorithm.

{kind=link}
Rust to WebAssembly
The AI is written in Rust and compiled to WebAssembly. The frontend is plain JavaScript and CSS. When you make a move, JavaScript sends the game state to the WASM module, which runs the minimax search and returns the AI's chosen move. On a modern machine this takes well under a second, even at depth three.
The game state is serialized between JavaScript and Rust using Serde via wasm-bindgen. Each call passes the full board state rather than maintaining mutable state inside the WASM module. This makes the interface stateless from the Rust side, which simplifies debugging and means the JavaScript frontend is the single source of truth for the game.
Playing it
The game highlights which sub-board you're allowed to play in. If you have a free choice, all open boards are highlighted. Won sub-boards display the winner's mark scaled up to fill the entire sub-board, making the meta-level game state easy to read at a glance. The UI shows a rules modal for anyone unfamiliar with the variant.
The AI is beatable, but it doesn't make obvious mistakes. It will punish you for sending it to a completed board unnecessarily and it has a good sense of when to sacrifice a sub-board to gain positional advantage at the meta level. Depth three is enough to see most tactical traps coming.