OpenMHz aggregates public police radio systems from cities across the US. Each system records individual dispatch calls as separate audio files, tagged with talkgroup, timestamp, and source. Blotter ingests those calls from twenty-four feeds across twenty-one metro areas, from Los Angeles to Chicago to Atlanta to Minneapolis. Each call is transcribed with Whisper, run through NLP to extract locations, geocoded to coordinates with city-aware region biasing, tagged with jurisdiction-specific police codes, summarized by a local LLM, and plotted on an interactive map. From dispatch call to map pin, the pipeline runs in about two minutes.
The pipeline
The system is three worker types running concurrently: a capture worker, an auto-scaling pool of transcription workers, and a processing worker. They communicate through Redis queues in a linear chain.
The capture worker polls the OpenMHz API for new calls across all twenty-four systems, downloads each call's audio, converts it to WAV, and uploads it to Google Cloud Storage. The transcription workers pick up those audio files, run them through Whisper on a GPU, extract police codes from the text, and write the transcripts to PostgreSQL. The processing worker takes the transcript text, runs named entity recognition to find locations, geocodes them with per-city region biasing, generates a one-sentence summary via Ollama, and writes the geolocated events to PostgreSQL.
This separation exists because the three stages have different resource profiles. Capture is I/O-bound: polling an API and writing to disk. Transcription is GPU-bound: Whisper's forward pass dominates the latency. Processing is API-bound: waiting on Google's NLP and Places endpoints. Running them as independent workers behind queues means a slow geocoding call doesn't back up transcription, and a Whisper model reload doesn't stall the audio capture. If any stage falls behind, its queue grows and the others keep running.
Capture
The original version of Blotter captured continuous audio streams from Broadcastify using FFmpeg, splitting them into arbitrary five-minute WAV segments. This worked but created problems: chunk boundaries split sentences in half, ad breaks from Broadcastify's sponsors contaminated transcripts, and the pipeline had no concept of individual radio calls. The Broadcastify capture path still exists as a fallback, but the primary architecture has moved on.
The current architecture uses OpenMHz, which provides per-call audio files via a JSON API. Each call is a single radio transmission, typically 5-60 seconds long, already segmented at natural boundaries. The capture worker runs a Playwright headless browser session with Cloudflare challenge solving (three retry attempts, with 30-minute backoff on IP blocks), then polls the API every three seconds for new calls.
For each new call, the worker downloads the M4A audio, converts it to 16 kHz mono WAV with FFmpeg, uploads the WAV to GCS, and enqueues a transcription task. Up to 32 concurrent downloads run via a thread pool. Each call carries a talkgroup identifier, so the feed ID becomes {system}-{talkgroup} and the display name resolves to something like "Chicago Police - Zone 5" or "LAPD Valley Bureau - Dispatch." A Redis set with 24-hour TTL tracks seen call IDs to prevent duplicate ingestion if the API returns overlapping pages.
Twenty-four feeds run in parallel across twenty-one metro areas: LAPD Valley and West bureaus, San Francisco PD, Chicago PD, Charlotte-Mecklenburg, Philadelphia, Seattle PSERN, Dallas, Portland, Prince George's County, Las Vegas, NW Harris County, Dane County, Monroe County, DC Fire and EMS, Hennepin County, Union County, Cleveland, Macomb County, St. Clair County, Suffolk County, Atlanta, Baltimore County, and Indianapolis.
Transcription
Whisper large-v3-turbo runs through Faster Whisper, a CTranslate2-based reimplementation that is significantly faster than the original PyTorch model while producing identical output. The transcription pool auto-scales between one and five threads on an A5000 24 GB GPU in float16: when the queue depth exceeds 50 chunks, the pool spins up additional threads; when it drops below 20, it scales back down. The pool checks queue depth every 10 seconds.
Voice activity detection runs as a preprocessing filter. Running Whisper on silence produces hallucinations: the model invents plausible-sounding dispatch text to fill the gap. The VAD filter, configured with a 500 ms minimum silence duration and 200 ms speech padding, strips silence before Whisper sees the audio. A separate silence detector (threshold -35 dB via FFmpeg's volumedetect) catches entirely dead chunks before they reach the model.
Each city gets its own initial prompt that biases Whisper's decoder toward local vocabulary. Prompts can be configured per system (e.g., chi_cpd.txt) or per individual feed (e.g., chi_cpd-11.txt), with a default fallback. The Chicago prompt includes "Districts 1 through 25" and local street names. The Philadelphia prompt includes signal codes used by PPD. The LAPD prompts include division names and LA-specific terminology. Getting these right matters: without the Chicago prompt, Whisper consistently misinterprets "Madison" (a major Chicago street) as a person's name. Each transcriber maintains a context window of the five most recent chunks per feed, providing continuity across calls.
Scanner codes
Police radio uses a dense vocabulary of numeric codes that vary by jurisdiction. The code extraction system applies per-feed regex patterns compiled from a hierarchy of code dictionaries. At the base layer are about 70 universal APCO 10-codes (10-4 for acknowledged, 10-20 for location, 10-80 for pursuit) and common response codes (code 1 through code 4). On top of those, each feed loads its state's penal codes: California codes for LA and San Francisco (187 for homicide, 211 for robbery, 459 for burglary, 5150 for psychiatric hold), Illinois codes for Chicago, Texas codes for Dallas and Houston, New York codes for Rochester and Suffolk County, and so on for fifteen state code sets.
The third layer is agency-specific codes. Chicago PD uses 19-adam (not bona fide), 19-boy (no person found), 19-frank (peace restored). Charlotte-Mecklenburg uses signal codes (signal 5 for robbery, signal 10 for shooting). Las Vegas Metro uses 400-series dispatch codes. Dallas uses signal 6 through signal 46. DC Fire and EMS uses box alarm, working fire, and task force designations. Every supported system has its own code dictionary, and the per-feed pattern is compiled once and cached. Matching runs longest-first to prevent "10" from consuming "10-80," and bare numbers that look like street addresses are filtered out.
Extracting locations from radio chatter
This is the hardest stage in the pipeline. Police radio is not structured data. Dispatchers say things like "we've got a 459 in progress at Florence and Normandie" or "Adam-12, respond to 1800 block of Wilshire" or "suspect vehicle last seen southbound on the 110." The task is to identify which parts of that text are locations and resolve them to coordinates on a map.
The primary extraction uses Google's Natural Language API for entity analysis. The API returns typed entities with salience scores. Entities tagged as LOCATION or ADDRESS are candidate locations. But the raw entity list needs heavy filtering before it's useful.
Each system has its own skip list that catches common false positives. LA's list filters LAPD division names (Hollywood, Wilshire, Newton, Harbor, Rampart, Hollenbeck, Devonshire, Foothill, Topanga, and others) and bureau-level terms (South Bureau, Central Bureau). Chicago's list filters Area North, Area Central, Area South, and Districts 1 through 25. All systems share a base list covering phonetic alphabet callsigns (Adam, Baker, Charlie, David), generic dispatch terms (suspect, victim, supervisor, dispatch), and cardinal directions when used alone.
Several plausibility filters apply beyond the skip lists. Entities shorter than three characters are dropped. Single-word entities without a street suffix (street, avenue, boulevard) are dropped, since they're almost always callsign fragments or common nouns. Entities must have a salience score above 0.03. Bare freeway references ("the 110 north") are filtered because they don't resolve to a point.
Intersection detection is a separate pass over the entity list. When two LOCATION or ADDRESS entities appear near each other in the source text, separated by "and," "at," "&," or "/," they are combined into an intersection reference. "Florence" and "Normandie" appearing near each other with "and" between them become "Florence and Normandie." Ordinal-street patterns ("5th and Main") get special handling. Cross-street intersections are the most common location format in police dispatch across all the cities in the system.
For transcripts where the NLP API returns no usable entities, a regex fallback scans for dispatch-anchor clauses that look like they contain locations: patterns with street addresses (a number followed by words and a street suffix), intersection constructs, or dispatch keywords (respond, suspect, code) near geographic terms. These are tagged with lower confidence but catch locations the ML model misses.
Geocoding
Each extracted location is resolved to coordinates using Google's Places API. The critical challenge with multi-city support is region biasing. A query for "Madison and State" needs to resolve to Chicago when it comes from chi_cpd and to Madison, Wisconsin when it comes from dane_com.
Every system maps to a SystemRegion with a display suffix ("Chicago, IL," "Philadelphia, PA") and a geographic bounding box. The geocoder extracts the system ID from the feed ID, looks up the corresponding region, and passes both the suffix and bounding box to the Places API. The suffix appends to the query string ("Madison and State, Chicago, IL"), and the bounding box constrains the locationbias parameter. For LA feeds, a second level of subdivision biases queries toward the specific LAPD division (Valley, West, South, Central, Long Beach) for even tighter geographic targeting. For intersections, the geocoder tries multiple phrasings: "intersection of A and B," "A & B," and the reverse order, taking the first valid result.
Two filters run after the API returns a candidate. The result must have a place type indicating a road: route, intersection, or street_address. The result name must share significant words with the query. And the coordinate must fall within the system's bounding box (with 0.15-degree padding). Anything outside is discarded. The geocoder uses an LRU cache with 4,096 entries to avoid redundant API calls for the same intersections.
Summarization
After geocoding, the processing worker generates a one-sentence summary of each event using Ollama running Qwen 2.5 7B (Q4_K_M quantization) locally on the same pod. The model receives the transcript text plus surrounding context (up to 20 transcripts from a two-minute window, or up to 30 from the same incident window) with a system prompt that asks for one sentence of at most 30 words covering the incident type, location, and key details. Temperature is set to 0.3 with a cap of 80 tokens. The output is truncated at the first sentence, capped at 200 characters. Summarization runs with a 45-second timeout and fails silently if Ollama is unreachable, so events still appear on the map without a summary.
Deduplication and incident windows
Without deduplication, the map fills with clusters of identical pins. A single incident generates multiple dispatch calls, officer check-ins, and status updates, all mentioning the same location within a few minutes.
Deduplication runs at two levels. At the database level, the events table enforces a unique constraint on (feed_id, archive_ts, normalized), so duplicate events with the same feed, timestamp, and location name are rejected on insert. At the pipeline level, the processor checks PostgreSQL for any event with the same normalized location within the last 10 minutes and within 0.002 degrees (roughly 220 meters) before inserting a new one.
Transcripts from the same feed are grouped into incident windows. When a new call arrives within 60 seconds of the previous call on the same feed, it joins the same window. A gap longer than 60 seconds starts a new window. The window_id travels through the pipeline, linking transcripts and events that belong to the same incident. The frontend uses this to fetch the full chain of radio traffic for an incident in a single query.
Database
The events land in two PostgreSQL 16 tables. scanner_transcripts stores the full transcript text, audio URL, timestamped segments, feed metadata, extracted police codes, and window ID. scanner_events stores geolocated events with coordinates, confidence scores, surrounding context, tags, window ID, and the Ollama-generated summary. Both tables carry a 7-day TTL enforced by periodic cleanup.
Full-text search uses pg_trgm with a GIN trigram index on the transcript column, supporting ILIKE queries across the entire corpus. Spatial queries filter on latitude and longitude columns directly, with indexes on both. An optional transcript_embeddings table stores 384-dimensional vectors from all-MiniLM-L6-v2 for future semantic search.
The frontend talks to the backend through a Starlette API running on the pod, exposed at api.blotter.fm via a Cloudflare Tunnel. The API provides endpoints for events (with time range and geo-box filtering), transcripts (surrounding, by incident, and by street), related events from other feeds, and full-text search. The tunnel means the pod doesn't need a public IP.
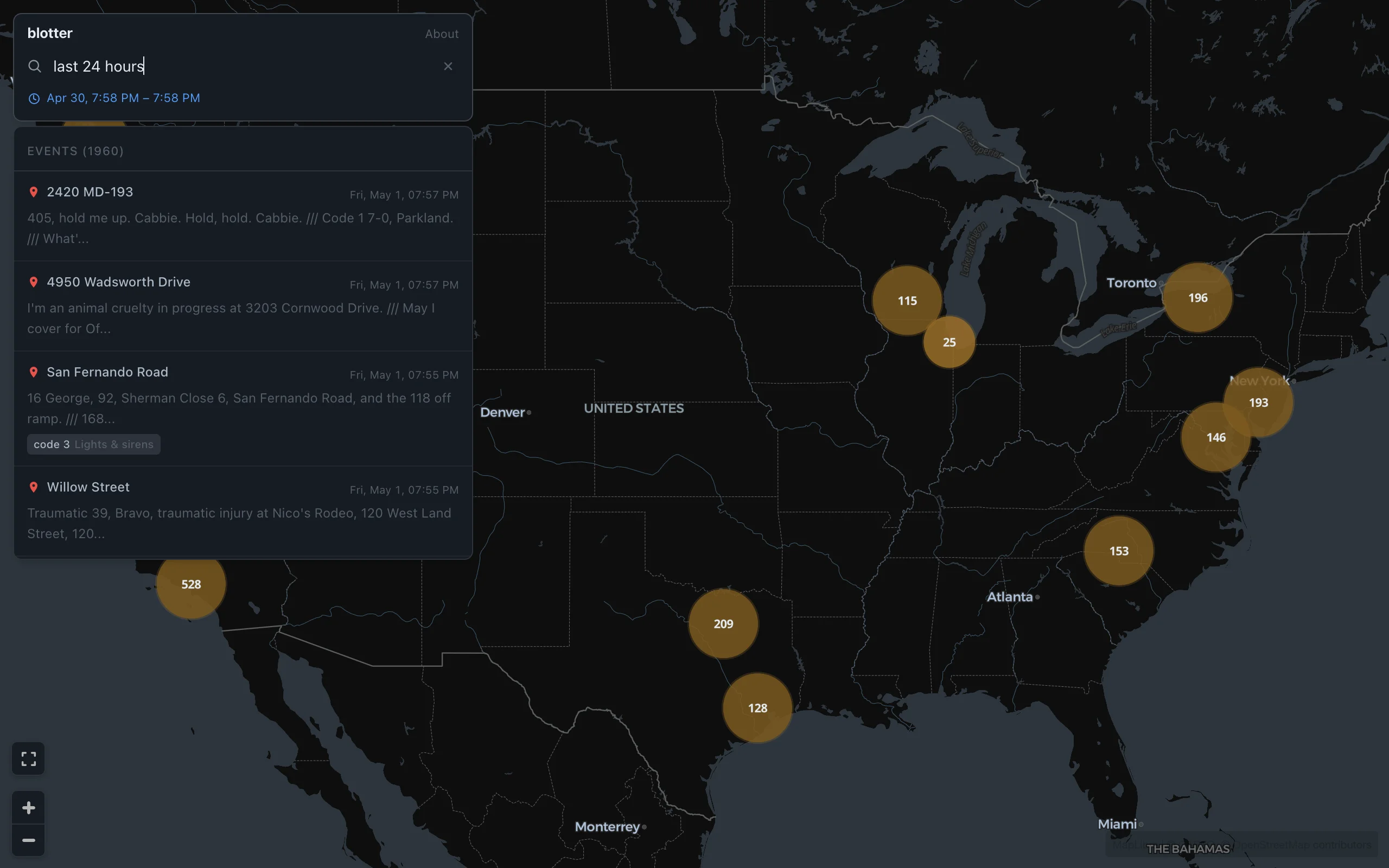
The map
The frontend is React 19 with MapLibre GL via react-map-gl. Events render as GeoJSON points with source-level clustering that merges nearby points into numbered circles. The default view shows the continental US; clicking a cluster zooms in by two levels until individual events become visible.
The search bar accepts natural language time expressions. Typing "last 6 hours," "yesterday," or "this morning" parses the input with chrono-node, a natural language date parser, and sets the query time range (defaulting to the last six hours). Whatever text remains after stripping the time expression becomes an ILIKE filter against the transcript, normalized location, feed ID, feed name, and police code tags.
Clicking an event on the map opens a detail panel showing the event time, feed, location, confidence, tags, and summary. The panel has four tabs. Incident Transcripts fetches all transcripts sharing the same window ID, showing the full chain of radio traffic for the incident. Surrounding fetches transcripts from the same feed within a configurable window (two to ten minutes). Street Filter narrows the surrounding transcripts to only those mentioning a specific street. Related Events searches for events from other feeds at the same location (within 0.003 degrees, roughly 330 meters) and within 30 minutes, correlating incidents across overlapping radio systems. Each transcript block has its own timestamp and audio player, and playback auto-advances through the calls in sequence.
Police codes in the transcripts (10-codes, penal codes, and signal codes) are tagged and displayed as color-coded chips with human-readable labels. The code dictionary covers universal codes (10-4, code 3), state penal codes for fifteen states, and agency-specific codes for every supported system.
The map polls for new events every 15 seconds. Relative time ranges ("last 6 hours") update their absolute boundaries on each poll, so the window rolls forward with the clock rather than going stale.
Infrastructure
The backend runs on a RunPod GPU pod with an A5000 24 GB. Nine services run under supervisord: Redis, PostgreSQL, Ollama, Cloudflare Tunnel, the Starlette API (on port 8080), the capture worker, the auto-scaling transcription pool, the processing worker, and a monitoring service. Data persists to a network volume that survives pod restarts.
The monitoring service checks transcript throughput every 20 minutes. If no new transcripts appear, it pushes an alert via ntfy.sh. A canary endpoint hit by an external cron job provides a second layer of health checking.
The frontend deploys to Cloudflare Pages. A Cloudflare Tunnel connects the pod's API to api.blotter.fm so the frontend can reach the backend without the pod needing a public IP. The system covers continuous transcription of twenty-four police radio feeds across twenty-one metro areas, real-time geocoded event mapping with LLM-generated summaries, full-text search across every transcript, incident correlation across feeds, and audio playback for every dispatch call.